📸 实机截图
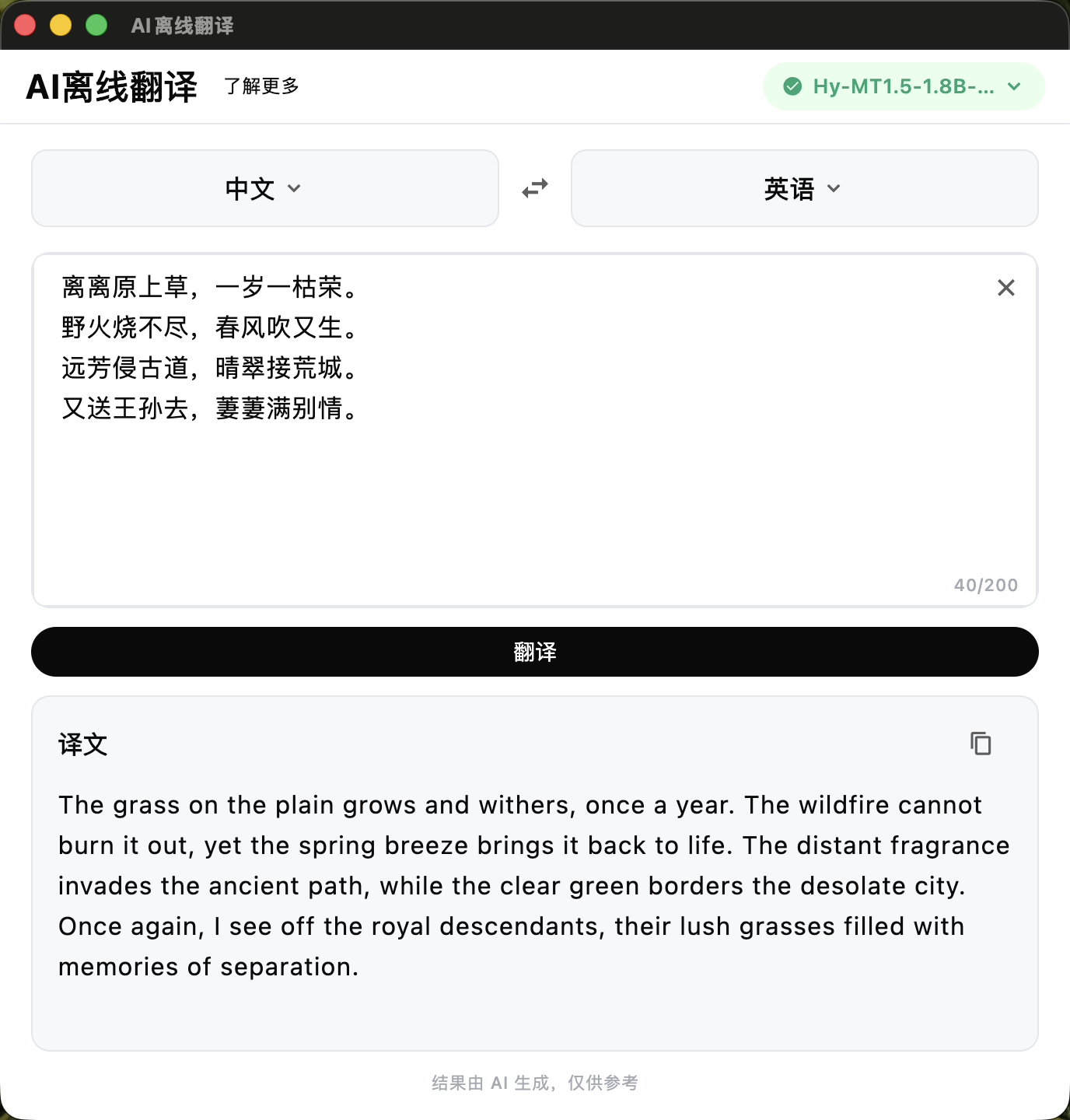
macOS

Android
这不是又一个云端 API 的壳——推理跑在你的手机 CPU 上
翻译数据不出手机,断网也能用。没有第三方服务器看到你翻译的内容。
llama.cpp 编译为 arm64 静态库链接进 App。不需要 CLI、不需要终端、不需要 root。
STQ1_0 1.25bit 量化——把 7GB 的原始模型压缩 16 倍,手机内存轻松承载。
一份 translator_engine.cpp 在两个平台共用。macOS 用 ObjC++,Android 用 JNI。
推理一个 token 就渲染一个 token,30–50ms 间隔,和 ChatGPT 一样的流式体验。
MIT 协议,代码公开。欢迎贡献、学习、二次开发。
从 Flutter UI 到底层 llama.cpp——四层架构,每层职责清晰
Hy-MT1.5 约 440MB(1.25bit 量化),手机端加载完全可行。该量化格式需 llama.cpp PR #22836 支持——仓库通过 submodule 固定到对应 commit。
prompt 构建(jinja chat template)→ tokenize → 推理循环(逐 token 生成至 EOS 或 128 token)→ 采样 → 解码为文本。可中途取消(atomic flag)。
核心是 translator_engine.hpp / .cpp——一份纯 C++ 引擎文件,
封装了模型加载、jinja chat template、tokenize、采样和生成循环。上层只调用三个方法:
// 纯 C++ 翻译引擎 — 不依赖 Flutter / 平台 struct TranslatorEngine { bool loadModel(const char* model_path); void translate(const char* text, char* out, size_t out_size); void cancel(); bool isModelLoaded(); };
这份引擎代码在两个平台 完全共用——macOS ObjC++ 和 Android JNI 直接调同一份 .cpp。
std::thread 中执行,不阻塞 Flutter UI。取消通过 std::atomic<bool> 标记。| 平台 | 桥接层 | 模型目录 | 编译方式 |
|---|---|---|---|
| macOS | ObjC++ wrapper → C++ | Application Support | Xcode 静态链接 |
| Android | JNI → C++ | files/models/ | CMake + NDK |
common_chat_templates_apply()。之前手写 token 序列导致输出全是乱码。